
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 알기쉬운 알고리즘
- coding test
- buffer
- Serialization
- 윤성우의 열혈 자료구조
- JSON
- C 언어 코딩 도장
- Algorithm
- Stack
- stream
- 메모리구조
- C programming
- Selection Sorting
- list 컬렉션
- ㅅ
- 윤성우 열혈자료구조
- datastructure
- 이스케이프 문자
- insertion sort
- 이것이 자바다
- R
- s
- Graph
- 혼자 공부하는 C언어
- Today
- Total
Engineering Note
[C] C언어로 Insertion Sort 구현 해보기 본문
[C] C언어로 Insertion Sort 구현 해보기
Software Engineer Kim 2021. 1. 10. 00:34
0,1,2,3 인덱스 까지 정렬이 되어 있고 4 인덱스 부터 마지막 까지 뒤죽 박죽인 배열부터 먼저 생각하자
이유는 삽입 정렬은 정렬된 부분에 삽입하는 알고리즘으로 정렬 되지 않은 4번인덱스 부터 구현해 보면서 코드 구현 과정을 이해 해야 편하다.
최종에 가서는 어디서 부터 정렬 되어 있는지 모르는 데이터의 상태를 정렬해야 되기 때문에 첫번째 인덱스는 혼자 있으므로 무조건 정렬된 상태로 인식해도 되고 두번째 인덱스부터 반복 삽입정렬을 구현하면 된다. 이때 반복문을 작성하기 위한 이해단계로 0,1,2,3 인덱스 까지 정렬이 되어 있고 4 인덱스 부터 마지막 까지 뒤죽 박죽인 배열부터 먼저 생각해서 내부 반복문이 어떻게 생성되었는지 확인해보려고 한다.
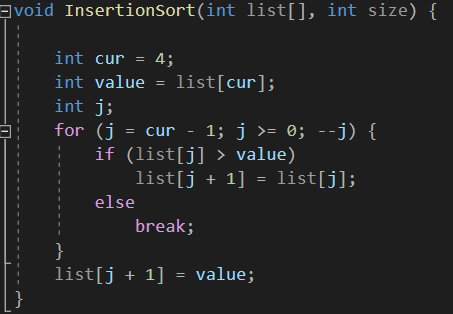
현재 인덱스를 나타내는 변수 cur에 Index번호 4를 대입하고 해당 값을 보존하기 위해 value에 보관 4인덱스의 아래 3번 인덱스 부터 0인덱스 까지 삽입할 위치를 찾는다. 삽입할 위치는 자신보다 큰 값이 나왔을 때 큰 값을 한칸 우측으로 옮긴다.(1회전시기에는 한칸 우측이 현재 인덱스 값이다.) 이 과정을 자신보다 작거나 같은 값이 나올 때 까지 반복한다. 그
리고 작거나 같은 값이 중간에 나오면 루프문을 빠져나가 마지막 비교한 값 우측에 삽입한다. (우측->+1의미)
else break;는 아래값들은 더 정렬 되어 있기 때문에 if 조건에 해당하지 않으면 loop문을 빠져나가야한다. 그래야 쓸데 없는 조건문을 검사할 필요 없을 뿐더러 j 값이 더이상 변경 되지 않은 상태에서 자기가 원래 있던 자리에 value 값을 다시 삽입할 수 있기 때문이다.

이제 이 cur 변수를 5, 6, 7 ... 마지막 인덱스 까지 반복하는 코드를 작성하면됨
하지만 현실에서는 어디서 부터 데이터가 정렬 되어있는지 아는 경우는 거의 없으므로 1번 인덱스(2번째 요소)를 cur로 두고 cur가 증하가도록 루프문을 돌리면된다.
왜냐하면 데이터가 하나만 있을때는 어떤 값이든 무조건 정렬이 된상태로 이해할 수 있다.(ex int list[1] ={100}; // 100은 혼자서 독립적으로 정렬된 상태이다.)
그러므로 0번 인덱스 혼자서는 독립적으로 정렬된 상태로 이해해도 된다. 당연한 얘기지만 이러한 것들이 컴퓨터 사이언스에서는 매우 중요하다.
'Programming Language > C programming' 카테고리의 다른 글
| [C] 16 -1 동적할당함수 (0) | 2021.02.12 |
|---|---|
| [C] temp 없이 Swap 하는 방법 (0) | 2021.01.31 |
| [C] C언어 강좌-2, C언어 컴파일 과정 (0) | 2021.01.26 |
| [C] 메모리의 구조 (0) | 2021.01.06 |
| [C] Stack frame (0) | 2021.01.06 |


